
Comment exploiter des informations non structurées ?
Les modes d’exploitation d’un corpus documentaire non structurée est souvent calqués sur le mode d’exploitation des bibliothèques, c’est-à-dire basés sur un plan de classement.
Or, lorsqu’on travaille dans un univers numérique, on constate les limites d’usage des plans de classement :
- Les utilisateurs ne maitrisent pas les concepts des plans de classements des documentalistes.
- Le volume, l’hétérogénéité et la dynamique des informations (évolutions des versions, par exemple) ne se prêtent pas à ces modes de gestion.
- Les outils numériques offrent bien d’autres moyens d’exploiter ces corpus.
Nous citerons dans cet article quatre approches complémentaires pour mieux exploiter des informations non structurées. Ainsi, on peut réduire l’intérêt et l’importance des plans de classement et permettre de valoriser des informations non structurées :
- L’indexation intégrale des contenus grâce aux moteurs « morphosyntaxiques, voire sémantiques, s’appuyant sur l’analyse grammaticale des contenus et proposant des recherches en langage naturel bien plus puissantes que les mots clés
- L’indexation intégrale des contenus par mots clés
- Le filtrage sur métadonnées (propriétés ou facettes) et/ou plan de classement
- L’extraction de chaines de caractères (à la « SQL »)
Les avantages & limites de chaque mode de recherche
La recherche en langage naturel
Elle permet aussi de s’affranchir des mots « non significatifs » qui génèrent du bruit et viennent « polluer » les réponses.
Cette approche réduit le bruit par explicitation de la pertinence des documents trouvés, évitant ainsi à l’utilisateur d’avoir à consulter des documents peu pertinents.
Dès lors qu’on ajoute des « couches » sémantiques à cette approche, par exemple via la mise en œuvre de « synonymes » (au sens large) des mots de la question, on réduit aussi le silence en permettant d’accéder à des documents parlant effectivement du sujet qui nous intéresse mais sur la base d’autres mots que ceux de sa question.
Les limites sont celles liés à l’analyse grammaticale. Par exemple les signes de ponctuation sont traités comme tels et les mots « codifiés » en contenant comme une référence normalisée (abréviation…) ne pourra être trouvée facilement.
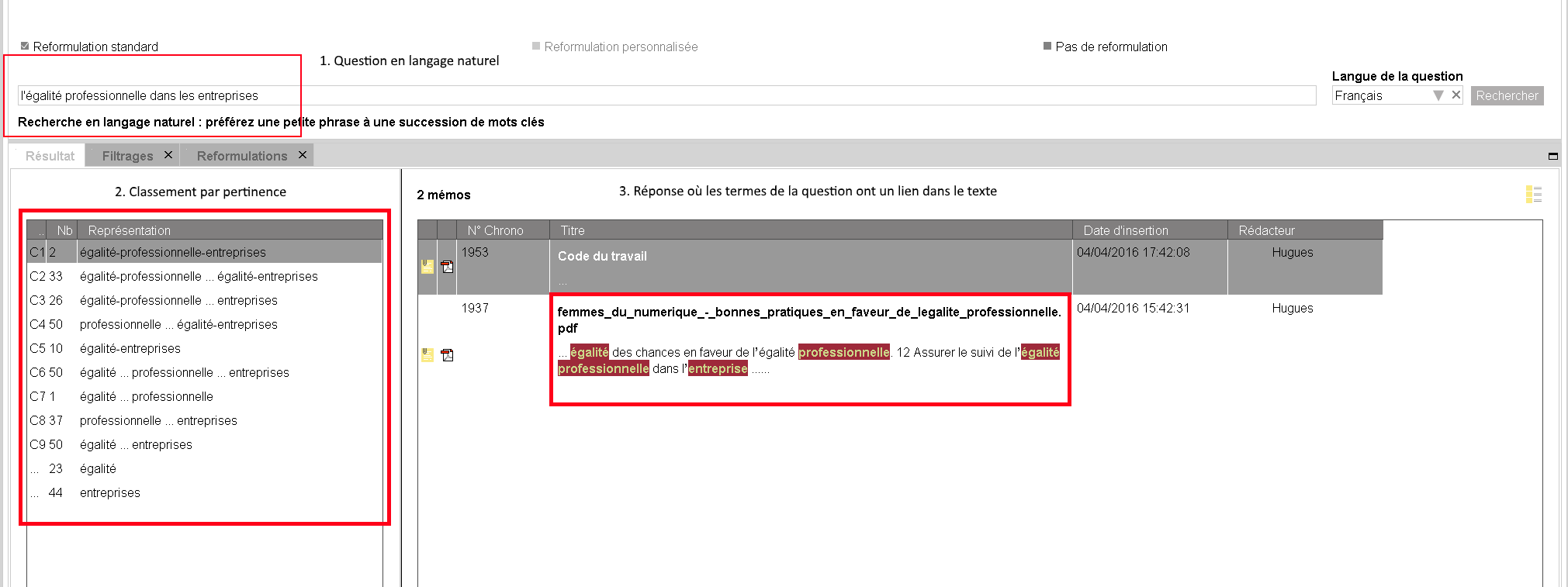
La recherche par mots-clés
La couche sémantique (synonymie, pluriels, conjugaisons et reconnaissance du genre) n’est pas applicable.

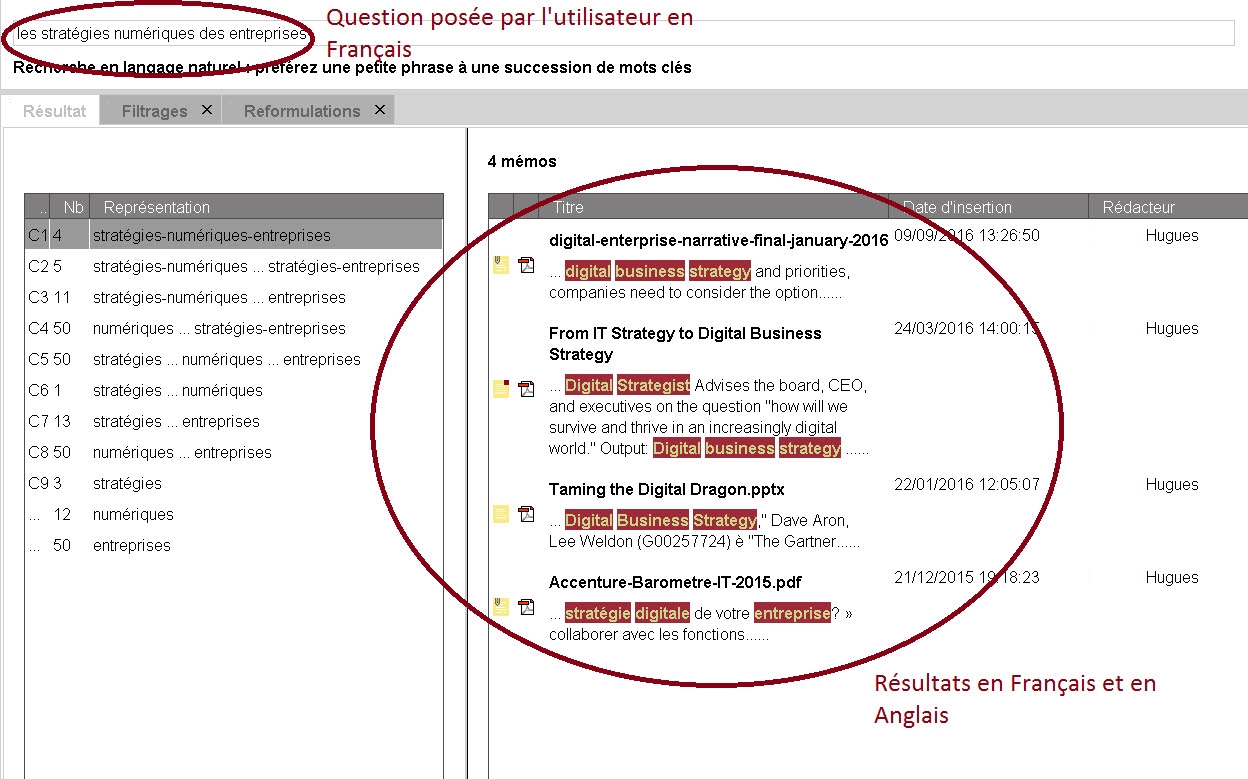
Cas particulier du multilinguisme & du crosslinguisme
L’approche par mots clés, en s’affranchissant de la notion de langue, permet d’interroger un corpus dans quasiment n’importe quelle langue.
La recherche en langage naturel, elle, ne le permet pas, puisqu’elle s’appuie sur l’analyse grammaticale des textes et est donc dépendante de la langue considérée.
Le crosslinguisme permet de s’affranchir quelque peu de cette limitation, puisqu’il permet de trouver des réponses dans d’autres langues que celles de la question, mais il faut disposer d’analyseur grammaticaux de chacune des langues souhaitées.
Ainsi l’approche par mots clés peut-être à la fois un complément pour aller chercher des « mots » particuliers composés de caractères que l’analyse grammaticale va traiter d’une manière inadaptée et pour interroger des corpus rédigés dans des langues non traités par le moteur considéré.
Le filtrage sur facettes
Dès lors qu’on opte pour une qualification par facettes, c’est-à-dire une forme de classement non basée sur un plan de classement mais sur des propriétés affectées à chaque document, on peut s’appuyer sur ces propriétés en les traitant comme des de filtres de recherche.
Ainsi si l’on a déclaré qu’un document était un compte-rendu et que l’on cherche un compte-rendu, interroger le système en indiquant cette propriété va permettre de réduire le périmètre de recherche et donc le nombre de résultats et ainsi trouver plus simplement le document souhaité.
L’intérêt de cette approche est qu’elle est bien plus simple qu’un plan de classement du terme, et que si les propriétés sont bien adaptées au contexte, elles seront tout à fait intuitives pour les utilisateurs qui pourront ainsi s’en servir simplement sans compétences ni formation particulière.
Mais, comme tout classement, cette qualification demande un effort supplémentaire à l’utilisateur, à l’entrée su système, c’est-à-dire lorsqu’il enregistre un document dans la base. Et que, s’il ne le fait pas, ou s’il se trompe, la recherche filtrée en permettra pas de retrouver le document en question. Le langage naturel, et sa pertinence, peut compenser ce type d’erreur, dès lors que la question posée est suffisamment adaptée, dans le cas de gros volume de documents, pour le retrouver.
La recherche par séquence de caractères (« pattern »)
Un dernier mode de recherche, non adapté à de gros volumes, pour des questions de performance, est la recherche dite « SQL », i.e. exploitant les chaines de caractères au sens strict du terme, c’est-à-dire ne traitant non plus des mots, à la façon des mots clés tels que précisé ci-dessus, mais une succession de caractères pouvant être seulement une partie d’un mot. Par exemple vouloir trouver la succession « chai » dans un texte, et donc toutes les occurrences contenant ces 4 lettres, mais pouvant être les mots chaines, chaises, etc.
Cette approche, associée aux opérateurs classiques tels que « contient », « commence par », « se termine par », …) permet de traiter des cas particuliers.
Elle ne peut être appliquée à de « vrais » corpus documentaires, mais seulement à des parties de ceux-ci, par exemple aux titres ou à des textes courts associés aux documents (commentaires ou descriptions).