
Qu’est-ce qu’un moteur de recherche linguistique ?
Dans le contexte professionnel, les informations utiles au quotidien se multiplient et se diversifient au-delà de ce qu’un être humain peut normalement appréhender. La difficulté d’organiser ces informations, ne serait-ce que pour les retrouver le moment venu, devient de plus en plus insurmontable, que ce soit au niveau collectif d’un projet ou d’une organisation, qu’au niveau de projets « étendus » ou multi-entreprises.
Dans ce contexte, disposer d’un outil de Gestion Electronique de Documents (GED) devient de plus en plus indispensable pour gagner en efficacité et gérer facilement l’ensemble des documents & informations d’une organisation. Cependant, encore faut-il pouvoir retrouver les documents stockés.
C’est pourquoi ANT’inno a intégré dès la conception de son logiciel de GED moteur de recherche linguistique. Ce dernier est développé en partenariat avec le Laboratoire d’Ingénierie de la Connaissance du CEA List.
Moteurs « statistiques », moteurs « sémantiques », qu’est-ce que c’est ?
Les moteurs de recherche les plus connus et usuels sont des moteurs dits « statistiques ». Ces derniers recherchent dans les document soumis des chaînes de caractère, et classent les documents en fonction du nombre d’occurrences de la ou des chaînes de caractères recherchées.
Cette méthode de recherche a l’inconvénient de générer beaucoup de « bruit », c’est-à-dire de noyer le ou les documents recherchés dans une masse de résultats non pertinents et donc de limiter leur efficacité pour des bases documentaires conséquentes.
Au contraire, notre moteur de recherche linguistique est beaucoup plus précis.
Comment fonctionne un moteur de recherche linguistique ?
Dans un premier temps, il va procéder à une analyse syntaxique des documents, c’est-à-dire rechercher les liens entre les mots du document. Dans un second temps, il va indexer automatiquement tout le contenu du document.
Pour retrouver les documents qui l’intéressent, l’utilisateur posera une question en langage naturel comme par exemple « Les stratégies numériques des entreprises ».
Le moteur va alors rechercher dans l’ensemble du corpus les documents où les notions de « Stratégie », de « Numérique » et d’« Entreprise » sont liées.
On voit dans l’illustration ci-dessous que plutôt que de fournir une longue liste de documents, le moteur présente comme résultat des classes de pertinences (C1, C2, C3, …). Ainsi, plus les notions de « Stratégie », de « Numérique » et d’« Entreprise » sont grammaticalement liées dans le document, (le lien étant représenté ci-dessous par un « – ») plus le moteur de recherche linguistique va considérer le document comme pertinent.
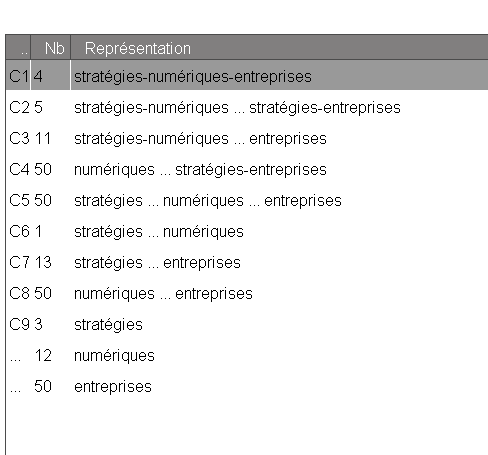
Un moteur de recherche qui gère les synonymies, les reformulations et les langues !
Intéressons-nous maintenant aux documents présents dans la classe C1 « stratégies-numériques- entreprises » :

Sur les quatre documents présentés ci-dessus, on voit que, non seulement ils correspondant bien à la question posée « Les stratégies numériques des entreprises » mais que le moteur a géré les synonymies ou reformulations – par exemple « digitale » et « numérique » mais a aussi remonté des résultats en anglais, on parle de cross-linguisme.
ANT’box intègre pour le moment quatre langues : Français, Anglais, Espagnol et Arabe. Nous travaillons en ce moment à l’intégration du Chinois (Mandarin).
Les avantages de l’approche linguistique
- Elle limite le « Bruit » : on accède de manière simple et intuitive aux documents les plus pertinents par rapport à la question posée sans être pollué par des documents parasites.
- Elle réduit le « Silence » : la reformulation permet de remonter des documents où les termes employés sont synonymes de ceux de la question.
Analyse sémantique + qualification manuelle = pertinence maximale & gain de temps
Allié dans ANT’box à un système de qualification manuelle des documents par méta-données (ou propriétés) qui permet de filtrer les résultats de la recherche, ce moteur de recherche fait de ANT’box la solution idéale pour exploiter des corpus documentaires conséquents, multilingues, de manière simple et sans se préoccuper de maintenir un plan de classement détaillé.