
Moins classer pour mieux travailler !
Les limites du classement des documents : la baisse de productivité
Une arborescence de répertoires est souvent l’approche privilégiée. Assez rigide, elle permet difficilement de s’adapter aux évolutions du marché ou tout simplement de l’organisation de l’entreprise. L’utilisateur en recherche d’un document ou d’une information va devoir naviguer de dossiers en sous-dossiers pour atteindre son but et pour peu qu’il ne sache pas où est stocké le document recherché, perdre un temps précieux.
De plus, avec l‘essor des organisations matricielles ou en mode projet, un même document, peut légitimement être classé dans plusieurs répertoires. Le risque de voir des doublons surgir n’est donc plus négligeable… Et dès lors, comment peut-on être sûr d’avoir la dernière version du document ?
Enfin, la difficulté à retrouver les documents ne fera que contribuer à l’inflation des e-mails, la messagerie servant la plupart du temps de support pour échanger des documents. Une étude Adobe montre d’ailleurs qu’un cadre européen passe 5,4 heures par jour à traiter ses e-mails…
La technologie est là pour vous aider !
Mais faut-il pour autant bannir cette notion de classement ? Pas si sûr : il suffit juste d’exploiter au mieux la technologie.
La classification par facettes, par exemple, permet de valoriser des propriétés, ou méta-données. Le document n’est plus déposé dans un dossier mais est stocké avec une ou plusieurs étiquettes qui le caractérisent. Ces propriétés seront autant de critères permettant à l’utilisateur de faire des requêtes en fonction de son point-de-vue. Elles pourront d’autant mieux être valorisées par les personnes alimentant la base documentaire qu’elles seront peu nombreuses et facilement compréhensibles dans le contexte de l’organisation utilisatrice.
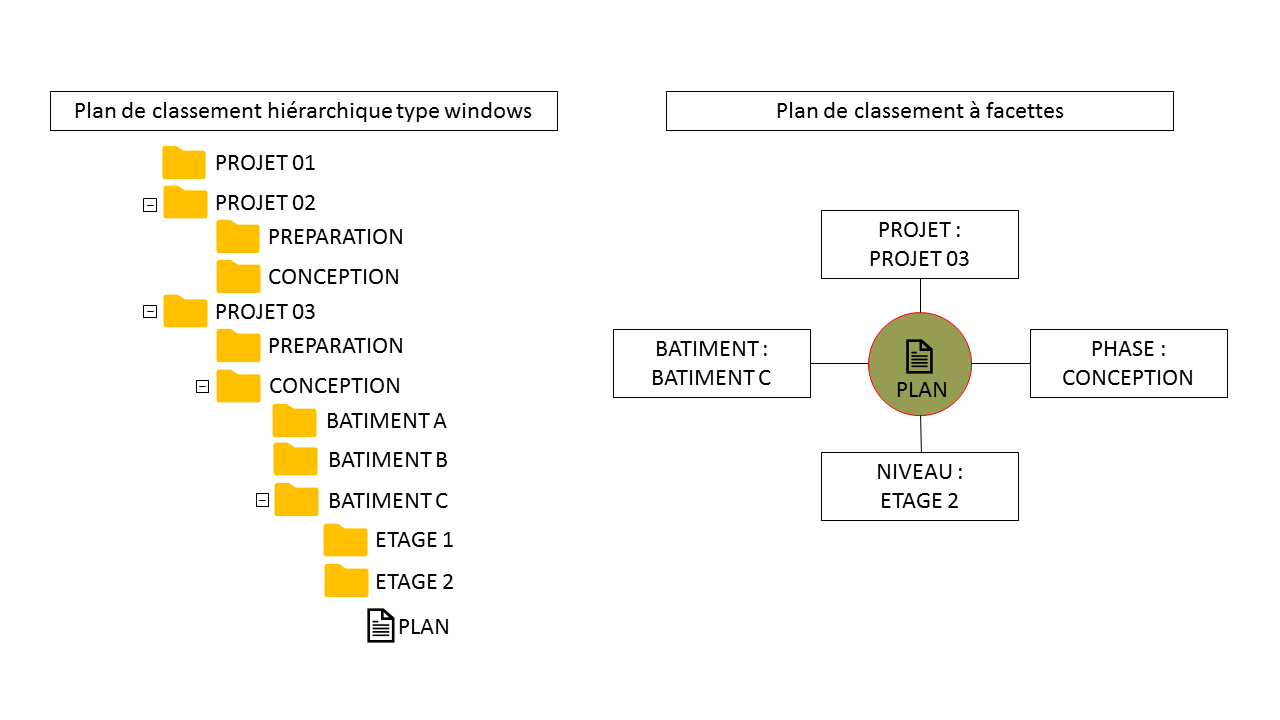
Plan de classement des documents hiérarchique et plan de classement à facettes pour un même document
Néanmoins, si l’on veut éviter de remplacer un classement hiérarchique rigide et complexe par un système de classification plus souple mais qui peut vite prendre une importance démesurée, un moteur de recherche puissant et pertinent peut vite devenir un allié indispensable. L’apport des technologies sémantiques pour indexer et analyser intégralement le contenu d’un document, proposer des reformulations par rapport aux termes de la question posée et explorer des bases documentaires en plusieurs langues permet aux utilisateurs d’explorer des bases documentaires volumineuses et de retrouver l’information recherchée en quelques secondes.
Si on envisage de coupler un moteur de recherche avec un système de classification par facettes dont les propriétés permettent de filtrer, c’est-à-dire de restreindre le périmètre de recherche, on peut arriver à des résultats impressionnants tout en simplifiant considérablement les processus de publication des documents.
Quelques éléments de volumétrie
Quelques éléments chiffrés permettent d’estimer la volumétrie de documents sur lesquels on peut travailler selon cette approche.
On peut considérer qu’une méta-données à 10 valeurs permet de caractériser 10 documents distincts, 2 méta-données permettent d’en caractériser 100, 3 pour 1000 etc.
On peut raisonnablement considérer par ailleurs qu’un moteur de recherche sémantique permet de traiter très facilement quelques milliers de documents. La combinaison de 2 méta-données et d’un moteur de recherche permet donc de retrouver très simplement un document parmi 1 million.
La technologie permet donc aujourd’hui aux organisations de moins classer pour mieux exploiter des corpus documentaires de plus en plus volumineux et hétérogènes, et permet à leurs collaborateurs de se concentrer sur leurs missions premières et d’être plus efficaces.